

Quando falamos de qualidade, um dos aspectos importantes de um ciclo de desenvolvimento de software é a gestão do conhecimento.
Uma das ferramentas mais utilizadas para esta finalidade é a documentação.
Mas infelizmente muitos de nós ainda não sabemos criar uma documentação efetiva.
Neste artigo, vamos entender o que é uma documentação efetiva e como isso ajuda a gerar cenários de teste de uma especificação.
O que é Documentação Efetiva#
É qualquer tipo de documento (ex: texto, imagem, tabelas) que gera valor para o leitor.
O seu documento pode estar:
- Claro
- Ortografia correta
- Organizado
Mas se o leitor não quiser ler, infelizmente a documentação não tem valor.
Ou seja, devemos sempre considerar o leitor.
Quando falamos de gestão de conhecimento, dois processos importantes devem acontecer em relação a documentação.
A externalização é quando queremos descrever o mundo real com alguma documentação.
Pode ser uma documentação sobre alguma funcionalidade, conhecimento, tela de sistema e etc.
A internalização é quando o leitor entende o mundo real através da documentação.
E esse passo é o importante que muitos de nós esquecemos.
Quanto mais fácil o processo de internalização, mais fácil o leitor perceber o valor do documento.
Documentação ruim treina o leitor a esperar nada da documentação -Beth Aitman
Então, como podemos gerar uma documentação efetiva?
Exemplo: Especificação#
Vou te passar dois tipos de documentação para a mesma especificação de uma funcionalidade. Qual você prefere?
A primeira documentação:

A segunda documentação:

A primeira documentação é o tipo de documentação que eu vi com mais frequência na minha experiência profissional.
O primeiro texto está correto mas infelizmente a informação não está estruturada. Isso exige do leitor um esforço adicional. Provavelmente o texto será relido algumas vezes, ou no pior caso, não será lido com atenção.
O segundo texto já tem um formato mais simples.
Passa a mesma informação mas estrutura ela em três partes: perfil do usuário, cenário e resultado esperado.
Para facilitar mais ainda, existe uma tabela de exemplo para facilitar os testes automatizados e manuais.
E existem cores para deixar mais claro ainda qual a responsabilidade de cada informação.
A dica é sempre então considerar o leitor e estruturar as informações de acordo.
Uma especificação é voltada para a equipe de desenvolvimento. Ela é utilizada para criar códigos que atendem os requisitos descritos. E também pode ser utilizado para fins de testes.
Então, vamos facilitar o trabalho do leitor e estruturar de uma maneira para que facilite a internalização da informação.
Padronizar a documentação#
Padronizar o tipo da documentação é extremamente importante pois facilita a escrita da documentação.
Se, por exemplo, todas as especificações exigirem:
- Perfil do usuário
- Cenário
- Resultado Esperado
- Exemplos
Facilita o modelo mental para pensar em cenários e casos de teste.
E tem um bônus adicional com a entrada de IA no mundo de desenvolvimento de software:
Você pode criar um texto padrão para passar para qualquer modelo e pedir para ele gerar os exemplos.
Utilizando a documentação padrão como prompt#
Quando você tem uma documentação bem estruturada e padronizada, você pode utilizar esta mesma documentação como texto para um modelo de LLM da sua escolha.
Para este artigo, estou usando o DeepSeek Chat com DeepThink ligado (DeepSeek R1):
O resultado foi esse:
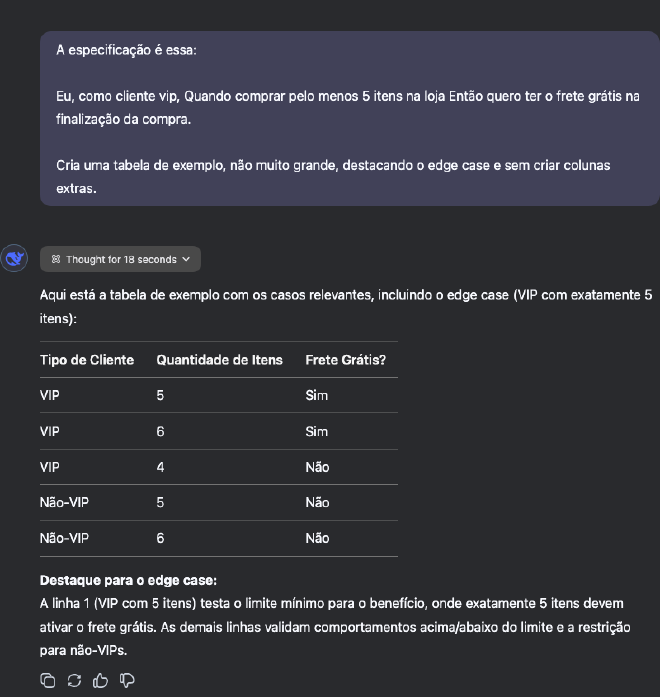
Ou seja, você pode deixar pronto o seguinte template de prompt:
Por exemplo, se a especificação for:
O seu prompt pode ser:
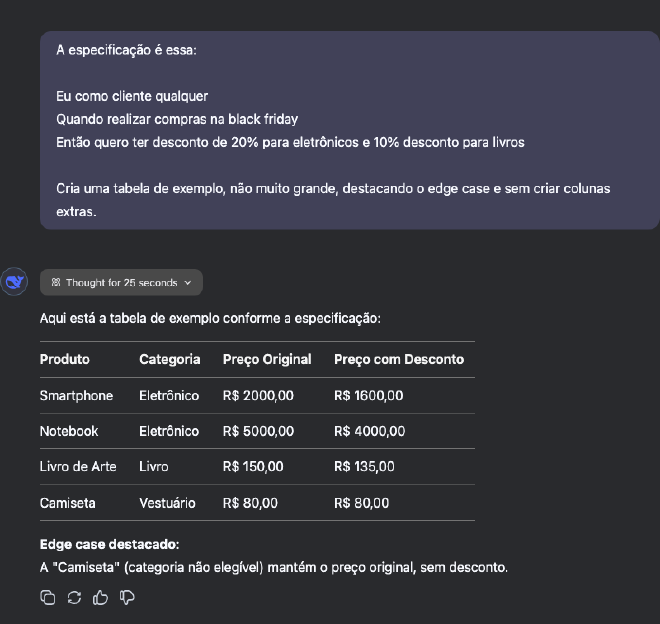
Testem o melhor prompt para ter o resultado esperado que vocês querem!
Para mais dicas de como melhorar o prompt, recomendo o seguinte site:
https://www.promptingguide.ai/pt
Após ter o template do prompt#
Quando o template do prompt ficar pronto e o resultado dela for satisfatório para maioria das especificações, podemos entrar no processo de automação de geração de cenários de teste.
Isso é possível pois vira uma tarefa repetitiva.
Essa é a parte onde podemos colaborar com desenvolvedores e criar um script para automatizar este processo.
Mas sempre verificando e incrementando o resultado final!
Por exemplo, se as especificações são escritas no Jira, podemos fazer um script onde:
- Busca todas as issues do Jira do sprint atual e recupera a descrição da issue com API Rest
- Montar o prompt utilizando o template criado e testado
- Passar para o modelo de preferência (Ex: ChatGPT ou DeepSeek R1) via API
- Retornar o resultado para o Jira e incrementar a descrição com o resultado gerado pelo LLM
Conclusão#
Uma documentação efetiva normalmente tem uma estrutura bem definida que facilita a leitura.
Este tipo de estrutura ajuda também o modelo de LLM sugerir o melhor texto para o pedido do usuário.
E quando bem testado o template do prompt, podemos automatizar o processo para contribuir na criação de cenários de testes.
Mas não precisamos parar por aí.
Podemos pedir para o LLM pegar um requisito com um texto sem estrutura e pedir para ele nos estruturar na forma padrão.
Ou seja, podemos pegar um texto anotado criado com a conversa do cliente e pedir para LLM estruturar o texto e já criar exemplos.
E assim por diante. O importante é realizar um passo de cada vez e ver como IA pode contribuir para o trabalho da equipe.
Mas uma nota super importante novamente: sempre verifique o resultado gerado pelo IA!
Se tiver curiosidade sobre o assunto, pode falar comigo!
🥒🥒 Espero que tenham curtido e até o próximo artigo! 🥒🥒