

Cobertura de código é uma das métricas mais utilizadas na área de desenvolvimento para tentar ajudar na qualidade do trabalho feito pela equipe.
Mas como qualquer métrica, é fácil de mal interpretar o valor e tirar conclusões erradas sobre testes, qualidade do código e a qualidade do produto.
Neste artigo vou falar rapidamente o que é, o que ela não mede e como utilizar a Cobertura de Código.
O que é#
Cobertura de código é uma métrica que diz qual a porcentagem da aplicação é executada pelo testes automatizados.
Normalmente são utilizadas linhas de código como medida.
Então, uma fórmula simples da métrica poderia ser:
Linhas executadas pelo teste / Total de linhas de código
Se um projeto tem 100 linhas de código e o seu teste automatizado executa 35 linhas, dizemos que a cobertura de código é de:
35 / 100 = 35%
O importante notar nesta métrica é que ele mede as linhas executadas pelo teste mas não diz se a linha foi bem testada!
E quais as consequências disso?
O que Cobertura de Código não mede#
Por exemplo, vamos supor que eu tenho uma calculadora que faz soma, subtração, multiplicação e divisão.
Se eu fizer um teste com todas as operações como:
calculadora.soma(1, 1)
calculadora.subtracao(1, 1)
calculadora.multiplicacao(1, 1)
calculadora.divisao(1, 1)
Consigo ter uma cobertura de 100% da aplicação. Mas veja que não verifiquei o resultado e nem testei outras possibilidades!
E mesmo que eu teste outros cenários e verifique o resultado, como por exemplo:
calculadora.soma(1, 1) == 2
calculadora.subtracao(1, 1) == 0
calculadora.multiplicacao(1, 1) == 1
calculadora.divisao(1, 1) == 1
Consigo o mesmo número que é de 100%, independente da qualidade dos testes!
Então a primeira lição importante:
Cobertura de Código não mede a qualidade dos seus testes!
E se quisermos colocar uma nova operação como potência na calculadora onde a Cobertura de Código está 100%?
A equipe pode demorar para implementar pois a qualidade do código é baixa. É difícil de alterar o código e difícil de entender o código.
Ou a equipe pode implementar com facilidade, pois o código é de alta qualidade.
Veja que, mesmo que o seu projeto tenha uma Cobertura de Código com valor de 100% pode acontecer as duas situações, pois este número só diz quantas linhas foram executadas pelo teste e não diz se o código está bem feito!
Então a segunda lição importante:
Cobertura de Código não mede a qualidade do código testado!
E agora imagine a seguinte situação:
- Uma aplicação com 10% de Cobertura de Código mas sem problemas em produção e usuários felizes
- Uma aplicação com 90% de Cobertura de Código mas com problemas em produção
É possível acontecer qualquer uma das situações?
Claro! E se sua resposta for não, provavelmente é por que você tem visto muitas aplicações com problemas e baixa Cobertura de Código.
É a famosa frase:
Correlação não implica em causalidade
Ou seja, falta de Cobertura de Código não implica necessariamente em quantidade alta de bugs em produção.
É possível ter muitos bugs em produção independentemente do valor da Cobertura de Código.
Então a última lição:
Cobertura de Código não mede a qualidade da sua aplicação!
Eu posso ter aplicações de ótima qualidade com 10% de Cobertura de Código ou 90% de Cobertura de Código.
Para que esta métrica serve então?
Como utilizar#
Existe uma tática simples.
É medir a tendência da Cobertura de Código ao longo do ciclo de desenvolvimento.
A primeira coisa a ser feita é medir o valor da Cobertura de Código atual do projeto.
Quando tiver o valor inicial da Cobertura de Código, usaremos este número como limite inferior da Cobertura de Código para o projeto.
Isto significa que a equipe** não deve baixar o valor da Cobertura de Código abaixo deste limite inferior **em nenhuma tarefa nova.
Se tiver alguma tarefa que faz a cobertura diminuir, devemos rejeitá-la.
Então, por exemplo, se um projeto com esta tática começa com 10% de Cobertura de Código no início do ano e termina o ano com 10,5%, ótimo! Garanto que melhorou e muito a qualidade do produto.
Se uma equipe tem uma Cobertura de Código de 90% no início do ano e caiu para 85% no final do ano, tenho certeza que está pior que o primeiro exemplo.
A explicação é simples.
Todo código novo ou alteração que fizemos no projeto é para atender alguma necessidade atual:
- Novas funcionalidades
- Correção de bugs
- Alteração de código
São nestes momentos que bugs novos podem surgir.
Então se existir um teste para cada alteração que fizermos no código, seja ele para implementar funcionalidades novas, corrigir bugs ou alteração para atender o cliente, a Cobertura de Código nunca diminui!
O valor se manter o mesma quando já temos o teste mas talvez tenha algum cenário que não tenha pego o bug. Pode aumentar quando criamos mais testes.
Só vai diminuir a Cobertura de Código quando existem códigos novos sem a execução feita pelos testes!
Então medir a tendência dos valores da Cobertura de Código pode indicar o comportamento adotado da equipe sobre testes automatizados.
Vamos analisar alguns gráficos para compreender melhor:
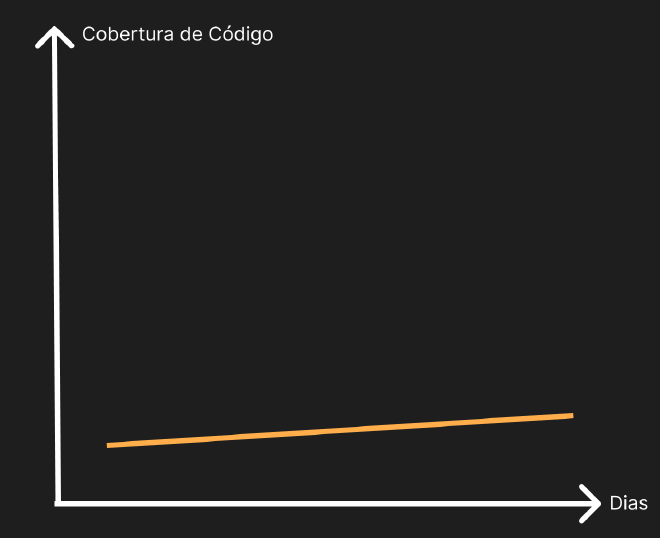
O gráfico acima mostra que o time tem conseguido manter a cobertura acima do limite inferior. Ou seja, códigos novos estão entrando com testes.
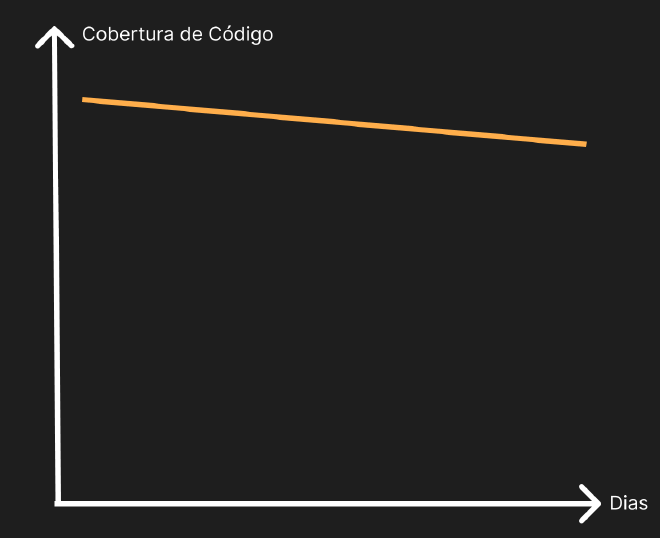
No gráfico acima conseguimos perceber que a cobertura está diminuindo, ou seja, estão escrevendo código novo sem testes! Um perigo.
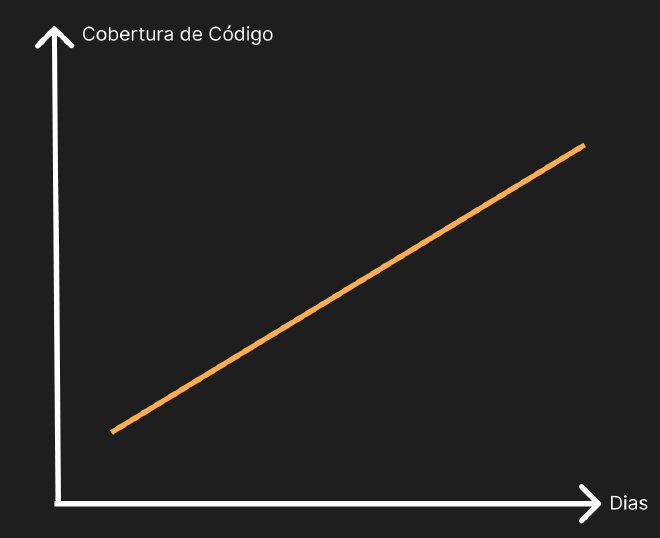
O gráfico acima mostra uma tendência que mais testes estão sendo criados sem muito código novo.
Essa tendência parece boa mas não é.
Provavelmente o objetivo da equipe é aumentar a Cobertura de Código em um número pré-definido.
Isso é ruim por um motivo simples.
Você não precisa escrever testes onde não há alteração!
Pensa comigo. Se o código não é alterado, podemos pensar em duas situações em relação a isso:
- O código não tem bugs
- O código tem bugs mas não está sendo utilizado
É um desperdício de esforço!
Então, por favor, nunca deixem um valor aleatório da Cobertura de Código ser utilizado como um objetivo a ser atingido!
Conclusão#
Se a Cobertura de Código está 10% ou 90%, o valor pontual não importa e nem diz nada sobre a qualidade.
Eu posso ter 10% de Cobertura de Código mas que verifica as principais funcionalidades do sistema e entrega valor para o cliente.
Eu posso ter 90% de Cobertura de Código mas que verifica funcionalidades que pouco ou nenhum usuário utiliza.
Mas se utilizarmos a Cobertura de Código como uma métrica orientadora de como devemos nos comportar em relação ao código novo, pode contribuir para o comportamento da equipe em relação à testes automatizados.
Lembrando novamente, infelizmente mesmo que a tendência da Cobertura de Código seja boa, isso não significa que a qualidade do código está melhorando! Para isso, existem outras métricas que podemos abordar nos próximos artigos.
Mas pelo menos sabemos que códigos novos estão sendo testado certo?
Se você tiver dúvidas, sugestões ou até correções, sinta-se à vontade para comentar ou falar diretamente comigo!
🥒🥒 Até o próximo artigo! 🥒🥒